
The audio deepfake (also known as voice cloning) is a type of artificial intelligence used to create convincing speech sentences that sound like specific people saying things they did not say. This technology was initially developed for various applications to improve human life. For example, it can be used to produce audiobooks, and also to help people who have lost their voices (due to throat disease or other medical problems) to get them back. Commercially, it has opened the door to several opportunities. This technology can also create more personalized digital assistants and natural-sounding text-to-speech as well as speech translation services.
Audio deepfakes, recently called audio manipulations, are becoming widely accessible using simple mobile devices or personal PCs. These tools have also been used to spread misinformation using audio. This has led to cybersecurity concerns among the global public about the side effects of using audio deepfakes. People can use them as a logical access voice spoofing technique, where they can be used to manipulate public opinion for propaganda, defamation, or terrorism. Vast amounts of voice recordings are daily transmitted over the Internet, and spoofing detection is challenging. Audio deepfake attackers have targeted individuals and organizations, including politicians and governments. In early 2020, some scammers used artificial intelligence-based software to impersonate the voice of a CEO to authorize a money transfer of about $35 million through a phone call. Therefore, it is necessary to authenticate any audio recording distributed to avoid spreading misinformation.
Categories
Audio deepfakes can be divided into three different categories:
Replay-based
Replay-based deepfakes are malicious works that aim to reproduce a recording of the interlocutor's voice.
There are two types: far-field detection and cut-and-paste detection. In far-field detection, a microphone recording of the victim is played as a test segment on a hands-free phone. On the other hand, cut-and-paste involves faking the requested sentence from a text-dependent system. Text-dependent speaker verification can be used to defend against replay-based attacks. A current technique that detects end-to-end replay attacks is the use of deep convolutional neural networks.
Synthetic-based
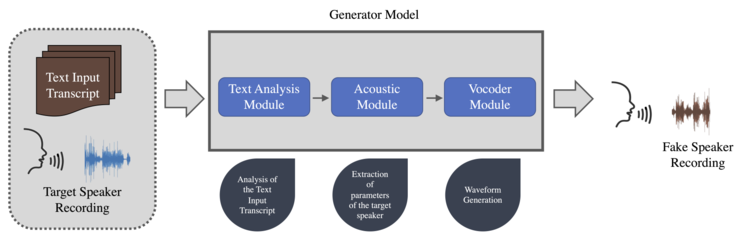
The category based on speech synthesis refers to the artificial production of human speech, using software or hardware system programs. Speech synthesis includes Text-To-Speech, which aims to transform the text into acceptable and natural speech in real-time, making the speech sound in line with the text input, using the rules of linguistic description of the text.
A classical system of this type consists of three modules: a text analysis model, an acoustic model, and a vocoder. The generation usually has to follow two essential steps. It is necessary to collect clean and well-structured raw audio with the transcripted text of the original speech audio sentence. Second, the Text-To-Speech model must be trained using these data to build a synthetic audio generation model.
Specifically, the transcribed text with the target speaker's voice is the input of the generation model. The text analysis module processes the input text and converts it into linguistic features. Then, the acoustic module extracts the parameters of the target speaker from the audio data based on the linguistic features generated by the text analysis module. Finally, the vocoder learns to create vocal waveforms based on the parameters of the acoustic features. The final audio file is generated, including the synthetic simulation audio in a waveform format, creating speech audio in the voice of many speakers, even those not in training.
The first breakthrough in this regard was introduced by WaveNet, a neural network for generating raw audio waveforms capable of emulating the characteristics of many different speakers. This network has been overtaken over the years by other systems which synthesize highly realistic artificial voices within everyone’s reach.
Unfortunately, Text-To-Speech is highly dependent on the quality of the voice corpus used to realize the system, and creating an entire voice corpus is expensive. Another disadvantage is that speech synthesis systems do not recognize periods or special characters. Also, ambiguity problems are persistent, as two words written in the same way can have different meanings.
Imitation-based
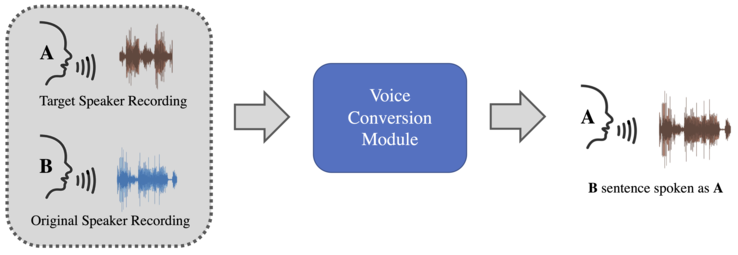
Audio deepfake based on imitation is a way of transforming an original speech from one speaker - the original - so that it sounds spoken like another speaker - the target one. An imitation-based algorithm takes a spoken signal as input and alters it by changing its style, intonation, or prosody, trying to mimic the target voice without changing the linguistic information. This technique is also known as voice conversion.
This method is often confused with the previous Synthetic-based method, as there is no clear separation between the two approaches regarding the generation process. Indeed, both methods modify acoustic-spectral and style characteristics of the speech audio signal, but the Imitation-based usually keeps the input and output text unaltered. This is obtained by changing how this sentence is spoken to match the target speaker's characteristics.
Voices can be imitated in several ways, such as using humans with similar voices that can mimic the original speaker. In recent years, the most popular approach involves the use of particular neural networks called Generative Adversarial Networks (GAN) due to their flexibility as well as high-quality results.
Then, the original audio signal is transformed to say a speech in the target audio using an imitation generation method that generates a new speech, shown in the fake one.
Detection methods
The audio deepfake detection task determines whether the given speech audio is real or fake.
Recently, this has become a hot topic in the forensic research community, trying to keep up with the rapid evolution of counterfeiting techniques.
In general, deepfake detection methods can be divided into two categories based on the aspect they leverage to perform the detection task. The first focuses on low-level aspects, looking for artifacts introduced by the generators at the sample level. The second, instead, focus on higher-level features representing more complex aspects as the semantic content of the speech audio recording.
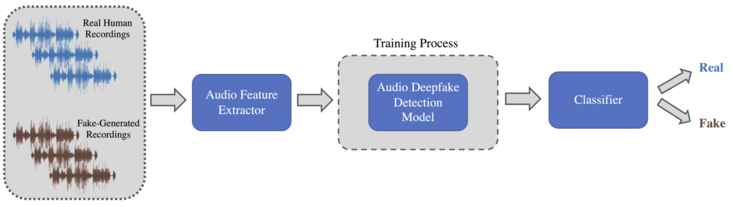
Many machine learning and deep learning models have been developed using different strategies to detect fake audio. Most of the time, these algorithms follow a three-steps procedure:
- Each speech audio recording must be preprocessed and transformed into appropriate audio features;
- The computed features are fed into the detection model, which performs the necessary operations, such as the training process, essential to discriminate between real and fake speech audio;
- The output is fed into the final module to produce a prediction probability of the Fake class or the Real one. Following the ASVspoof challenge nomenclature, the Fake audio is indicated with the term "Spoof," the Real instead is called "Bonafide."
Over the years, many researchers have shown that machine learning approaches are more accurate than deep learning methods, regardless of the features used. However, the scalability of machine learning methods is not confirmed due to excessive training and manual feature extraction, especially with many audio files. Instead, when deep learning algorithms are used, specific transformations are required on the audio files to ensure that the algorithms can handle them.
There are several open-source implementations of different detection methods, and usually many research groups release them on a public hosting service like GitHub.
Open challenges and future research direction
The audio deepfake is a very recent field of research. For this reason, there are many possibilities for development and improvement, as well as possible threats that adopting this technology can bring to our daily lives. The most important ones are listed below.
Deepfake generation
Regarding the generation, the most significant aspect is the credibility of the victim, i.e., the perceptual quality of the audio deepfake.
Several metrics determine the level of accuracy of audio deepfake generation, and the most widely used is the MOS (Mean Opinion Score), which is the arithmetic average of user ratings. Usually, the test to be rated involves perceptual evaluation of sentences made by different speech generation algorithms. This index showed that audio generated by algorithms trained on a single speaker has a higher MOS.
The sampling rate also plays an essential role in detecting and generating audio deepfakes. Currently, available datasets have a sampling rate of around 16 kHz, significantly reducing speech quality. An increase in the sampling rate could lead to higher quality generation.
Deepfake detection
Focusing on the detection part, one principal weakness affecting recent models is the adopted language.
Most studies focus on detecting audio deepfake in the English language, not paying much attention to the most spoken languages like Chinese and Spanish, as well as Hindi and Arabic.
It is also essential to consider more factors related to different accents that represent the way of pronunciation strictly associated with a particular individual, location, or nation. In other fields of audio, such as speaker recognition, the accent has been found to influence the performance significantly, so it is expected that this feature could affect the models' performance even in this detection task.
In addition, the excessive preprocessing of the audio data has led to a very high and often unsustainable computational cost. For this reason, many researchers have suggested following a Self-Supervised Learning approach, dealing with unlabeled data to work effectively in detection tasks and improving the model's scalability, and, at the same time, decreasing the computational cost.
Training and testing models with real audio data is still an underdeveloped area. Indeed, using audio with real-world background noises can increase the robustness of the fake audio detection models.
In addition, most of the effort is focused on detecting Synthetic-based audio deepfakes, and few studies are analyzing imitation-based due to their intrinsic difficulty in the generation process.
Defense against deepfakes
Over the years, there has been an increase in techniques aimed at defending against malicious actions that audio deepfake could bring, such as identity theft and manipulation of speeches by the nation's governors.
To prevent deepfakes, some suggest using blockchain and other distributed ledger technologies (DLT) to identify the provenance of data and track information.
Extracting and comparing affective cues corresponding to perceived emotions from digital content has also been proposed to combat deepfakes.
Another critical aspect concerns the mitigation of this problem. It has been suggested that it would be better to keep some proprietary detection tools only for those who need them, such as fact-checkers for journalists. That way, those who create the generation models, perhaps for nefarious purposes, would not know precisely what features facilitate the detection of a deepfake, discouraging possible attackers.
To improve the detection instead, researchers are trying to generalize the process, looking for preprocessing techniques that improve performance and testing different loss functions used for training.
Research programs
Numerous research groups worldwide are working to recognize media manipulations; i.e., audio deepfakes but also image and video deepfake. These projects are usually supported by public or private funding and are in close contact with universities and research institutions.
For this purpose, the Defense Advanced Research Projects Agency (DARPA) runs the Semantic Forensics (SemaFor). Leveraging some of the research from the Media Forensics (MediFor) program, also from DARPA, these semantic detection algorithms will have to determine whether a media object has been generated or manipulated, to automate the analysis of media provenance and uncover the intent behind the falsification of various content.
Another research program is the Preserving Media Trustworthiness in the Artificial Intelligence Era (PREMIER) program, funded by the Italian Ministry of Education, University and Research (MIUR) and run by five Italian universities. PREMIER will pursue novel hybrid approaches to obtain forensic detectors that are more interpretable and secure.
Public challenges
In the last few years, numerous challenges have been organized to push this field of audio deepfake research even further.
The most famous world challenge is the ASVspoof, the Automatic Speaker Verification Spoofing and Countermeasures Challenge. This challenge is a bi-annual community-led initiative that aims to promote the consideration of spoofing and the development of countermeasures.
Another recent challenge is the ADD—Audio Deepfake Detection—which considers fake situations in a more real-life scenario.
Also the Voice Conversion Challenge is a bi-annual challenge, created with the need to compare different voice conversion systems and approaches using the same voice data.