
In computer science, Ukkonen's algorithm is a linear-time, online algorithm for constructing suffix trees, proposed by Esko Ukkonen in 1995. The algorithm begins with an implicit suffix tree containing the first character of the string. Then it steps through the string, adding successive characters until the tree is complete. This order addition of characters gives Ukkonen's algorithm its "on-line" property. The original algorithm presented by Peter Weiner proceeded backward from the last character to the first one from the shortest to the longest suffix. A simpler algorithm was found by Edward M. McCreight, going from the longest to the shortest suffix.
Implicit suffix tree
While generating suffix tree using Ukkonen's algorithm, we will see implicit suffix tree in intermediate steps depending on characters in string S. In implicit suffix trees, there will be no edge with $ (or any other termination character) label and no internal node with only one edge going out of it.
High level description of Ukkonen's algorithm
Ukkonen's algorithm constructs an implicit suffix tree Ti for each prefix S[1...i] of S (S being the string of length n). It first builds T1 using 1st character, then T2 using 2nd character, then T3 using 3rd character, ..., Tn using the nth character. You can find the following characteristics in a suffix tree that uses Ukkonen's algorithm:
- Implicit suffix tree Ti+1 is built on top of implicit suffix tree Ti .
- At any given time, Ukkonen's algorithm builds the suffix tree for the characters seen so far and so it has on-line property, allowing the algorithm to have an execution time of O(n).
- Ukkonen's algorithm is divided into n phases (one phase for each character in the string with length n).
- Each phase i+1 is further divided into i+1 extensions, one for each of the i+1 suffixes of S[1...i+1].
Suffix extension is all about adding the next character into the suffix tree built so far. In extension j of phase i+1, algorithm finds the end of S[j...i] (which is already in the tree due to previous phase i) and then it extends S[j...i] to be sure the suffix S[j...i+1] is in the tree. There are three extension rules:
- If the path from the root labelled S[j...i] ends at a leaf edge (i.e., S[i] is last character on leaf edge), then character S[i+1] is just added to the end of the label on that leaf edge.
- if the path from the root labelled S[j...i] ends at a non-leaf edge (i.e., there are more characters after S[i] on path) and next character is not S[i+1], then a new leaf edge with label S[i+1] and number j is created starting from character S[i+1]. A new internal node will also be created if S[1...i] ends inside (in between) a non-leaf edge.
- If the path from the root labelled S[j..i] ends at a non-leaf edge (i.e., there are more characters after S[i] on path) and next character is S[i+1] (already in tree), do nothing.
One important point to note is that from a given node (root or internal), there will be one and only one edge starting from one character. There will not be more than one edge going out of any node starting with the same character.
Run time
The naive implementation for generating a suffix tree going forward requires O(n2) or even O(n3) time complexity in big O notation, where n is the length of the string. By exploiting a number of algorithmic techniques, Ukkonen reduced this to O(n) (linear) time, for constant-size alphabets, and O(n log n) in general, matching the runtime performance of the earlier two algorithms.
Ukkonen's algorithm example
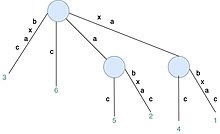
To better illustrate how a suffix tree using Ukkonen's algorithm is constructed, we can use the following example:
S=xabxac
- Start with an empty root node.
- Construct T1 for S[1] by adding the first character of the string. Rule 2 applies, which creates a new leaf node.
- Construct T2 for S[1...2] by adding suffixes of xa (xa and a). Rule 1 applies, which extends the path label in existing leaf edge. Rule 2 applies, which creates a new leaf node.
- Construct T3 for S[1...3] by adding suffixes of xab (xab, ab and b). Rule 1 applies, which extends the path label in existing leaf edge. Rule 2 applies, which creates a new leaf node.
- Construct T4 for S[1...4] by adding suffixes of xabx (xabx, abx, bx and x). Rule 1 applies, which extends the path label in existing leaf edge. Rule 3 applies, do nothing.
- Constructs T5 for S[1...5] by adding suffixes of xabxa (xabxa, abxa, bxa, xa and a). Rule 1 applies, which extends the path label in existing leaf edge. Rule 3 applies, do nothing.
- Constructs T6 for S[1...6] by adding suffixes of xabxac (xabxac, abxac, bxac, xac, ac and c). Rule 1 applies, which extends the path label in existing leaf edge. Rule 2 applies, which creates a new leaf node (in this case, three new lead edges and two new internal nodes are created).
External links
- Detailed explanation in plain English
- Fast String Searching With Suffix Trees Mark Nelson's tutorial. Has an implementation example written with C++.
- Implementation in C with detailed explanation
- Lecture slides by Guy Blelloch
- Ukkonen's homepage
- Text-Indexing project (Ukkonen's linear-time construction of suffix trees)
- Implementation in C Part 1 Part 2 Part 3 Part 4 Part 5 Part 6