

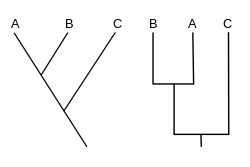
A cladogram (from Greek clados "branch" and gramma "character") is a diagram used in cladistics to show relations among organisms. A cladogram is not, however, an evolutionary tree because it does not show how ancestors are related to descendants, nor does it show how much they have changed, so many differing evolutionary trees can be consistent with the same cladogram. A cladogram uses lines that branch off in different directions ending at a clade, a group of organisms with a last common ancestor. There are many shapes of cladograms but they all have lines that branch off from other lines. The lines can be traced back to where they branch off. These branching off points represent a hypothetical ancestor (not an actual entity) which can be inferred to exhibit the traits shared among the terminal taxa above it. This hypothetical ancestor might then provide clues about the order of evolution of various features, adaptation, and other evolutionary narratives about ancestors. Although traditionally such cladograms were generated largely on the basis of morphological characters, DNA and RNA sequencing data and computational phylogenetics are now very commonly used in the generation of cladograms, either on their own or in combination with morphology.
Generating a cladogram
Molecular versus morphological data
The characteristics used to create a cladogram can be roughly categorized as either morphological (synapsid skull, warm blooded, notochord, unicellular, etc.) or molecular (DNA, RNA, or other genetic information). Prior to the advent of DNA sequencing, cladistic analysis primarily used morphological data. Behavioral data (for animals) may also be used.
As DNA sequencing has become cheaper and easier, molecular systematics has become a more and more popular way to infer phylogenetic hypotheses. Using a parsimony criterion is only one of several methods to infer a phylogeny from molecular data. Approaches such as maximum likelihood, which incorporate explicit models of sequence evolution, are non-Hennigian ways to evaluate sequence data. Another powerful method of reconstructing phylogenies is the use of genomic retrotransposon markers, which are thought to be less prone to the problem of reversion that plagues sequence data. They are also generally assumed to have a low incidence of homoplasies because it was once thought that their integration into the genome was entirely random; this seems at least sometimes not to be the case, however.

Plesiomorphies and synapomorphies
Researchers must decide which character states are "ancestral" (plesiomorphies) and which are derived (synapomorphies), because only synapomorphic character states provide evidence of grouping. This determination is usually done by comparison to the character states of one or more outgroups. States shared between the outgroup and some members of the in-group are symplesiomorphies; states that are present only in a subset of the in-group are synapomorphies. Note that character states unique to a single terminal (autapomorphies) do not provide evidence of grouping. The choice of an outgroup is a crucial step in cladistic analysis because different outgroups can produce trees with profoundly different topologies.
Homoplasies
A homoplasy is a character state that is shared by two or more taxa due to some cause other than common ancestry. The two main types of homoplasy are convergence (evolution of the "same" character in at least two distinct lineages) and reversion (the return to an ancestral character state). Characters that are obviously homoplastic, such as white fur in different lineages of Arctic mammals, should not be included as a character in a phylogenetic analysis as they do not contribute anything to our understanding of relationships. However, homoplasy is often not evident from inspection of the character itself (as in DNA sequence, for example), and is then detected by its incongruence (unparsimonious distribution) on a most-parsimonious cladogram. Note that characters that are homoplastic may still contain phylogenetic signal.
A well-known example of homoplasy due to convergent evolution would be the character, "presence of wings". Although the wings of birds, bats, and insects serve the same function, each evolved independently, as can be seen by their anatomy. If a bird, bat, and a winged insect were scored for the character, "presence of wings", a homoplasy would be introduced into the dataset, and this could potentially confound the analysis, possibly resulting in a false hypothesis of relationships. Of course, the only reason a homoplasy is recognizable in the first place is because there are other characters that imply a pattern of relationships that reveal its homoplastic distribution.
What is not a cladogram
A cladogram is the diagrammatic result of an analysis, which groups taxa on the basis of synapomorphies alone. There are many other phylogenetic algorithms that treat data somewhat differently, and result in phylogenetic trees that look like cladograms but are not cladograms. For example, phenetic algorithms, such as UPGMA and Neighbor-Joining, group by overall similarity, and treat both synapomorphies and symplesiomorphies as evidence of grouping, The resulting diagrams are phenograms, not cladograms, Similarly, the results of model-based methods (Maximum Likelihood or Bayesian approaches) that take into account both branching order and "branch length," count both synapomorphies and autapomorphies as evidence for or against grouping, The diagrams resulting from those sorts of analysis are not cladograms, either.
Cladogram selection
There are several algorithms available to identify the "best" cladogram. Most algorithms use a metric to measure how consistent a candidate cladogram is with the data. Most cladogram algorithms use the mathematical techniques of optimization and minimization.
In general, cladogram generation algorithms must be implemented as computer programs, although some algorithms can be performed manually when the data sets are modest (for example, just a few species and a couple of characteristics).
Some algorithms are useful only when the characteristic data are molecular (DNA, RNA); other algorithms are useful only when the characteristic data are morphological. Other algorithms can be used when the characteristic data includes both molecular and morphological data.
Algorithms for cladograms or other types of phylogenetic trees include least squares, neighbor-joining, parsimony, maximum likelihood, and Bayesian inference.
Biologists sometimes use the term parsimony for a specific kind of cladogram generation algorithm and sometimes as an umbrella term for all phylogenetic algorithms.
Algorithms that perform optimization tasks (such as building cladograms) can be sensitive to the order in which the input data (the list of species and their characteristics) is presented. Inputting the data in various orders can cause the same algorithm to produce different "best" cladograms. In these situations, the user should input the data in various orders and compare the results.
Using different algorithms on a single data set can sometimes yield different "best" cladograms, because each algorithm may have a unique definition of what is "best".
Because of the astronomical number of possible cladograms, algorithms cannot guarantee that the solution is the overall best solution. A nonoptimal cladogram will be selected if the program settles on a local minimum rather than the desired global minimum. To help solve this problem, many cladogram algorithms use a simulated annealing approach to increase the likelihood that the selected cladogram is the optimal one.
The basal position is the direction of the base (or root) of a rooted phylogenetic tree or cladogram. A basal clade is the earliest clade (of a given taxonomic rank[a]) to branch within a larger clade.
Statistics
Incongruence length difference test (or partition homogeneity test)
The incongruence length difference test (ILD) is a measurement of how the combination of different datasets (e.g. morphological and molecular, plastid and nuclear genes) contributes to a longer tree. It is measured by first calculating the total tree length of each partition and summing them. Then replicates are made by making randomly assembled partitions consisting of the original partitions. The lengths are summed. A p value of 0.01 is obtained for 100 replicates if 99 replicates have longer combined tree lengths.
Measuring homoplasy
Some measures attempt to measure the amount of homoplasy in a dataset with reference to a tree, though it is not necessarily clear precisely what property these measures aim to quantify
Consistency index
The consistency index (CI) measures the consistency of a tree to a set of data – a measure of the minimum amount of homoplasy implied by the tree. It is calculated by counting the minimum number of changes in a dataset and dividing it by the actual number of changes needed for the cladogram. A consistency index can also be calculated for an individual character i, denoted ci.
Besides reflecting the amount of homoplasy, the metric also reflects the number of taxa in the dataset, (to a lesser extent) the number of characters in a dataset, the degree to which each character carries phylogenetic information, and the fashion in which additive characters are coded, rendering it unfit for purpose.
ci occupies a range from 1 to 1/[n.taxa/2] in binary characters with an even state distribution; its minimum value is larger when states are not evenly spread. In general, for a binary or non-binary character with , ci occupies a range from 1 to .


Retention index
The retention index (RI) was proposed as an improvement of the CI "for certain applications" This metric also purports to measure of the amount of homoplasy, but also measures how well synapomorphies explain the tree. It is calculated taking the (maximum number of changes on a tree minus the number of changes on the tree), and dividing by the (maximum number of changes on the tree minus the minimum number of changes in the dataset).
The rescaled consistency index (RC) is obtained by multiplying the CI by the RI; in effect this stretches the range of the CI such that its minimum theoretically attainable value is rescaled to 0, with its maximum remaining at 1. The homoplasy index (HI) is simply 1 − CI.
Homoplasy Excess Ratio
This measures the amount of homoplasy observed on a tree relative to the maximum amount of homoplasy that could theoretically be present – 1 − (observed homoplasy excess) / (maximum homoplasy excess). A value of 1 indicates no homoplasy; 0 represents as much homoplasy as there would be in a fully random dataset, and negative values indicate more homoplasy still (and tend only to occur in contrived examples). The HER is presented as the best measure of homoplasy currently available.
See also
External links
-
 Media related to Cladograms at Wikimedia Commons
Media related to Cladograms at Wikimedia Commons
| Relevant fields | ||
|---|---|---|
| Basic concepts | ||
| Inference methods | ||
| Current topics | ||
| Group traits | ||
| Group types | ||
| Nomenclature | ||