
The High-performance Integrated Virtual Environment (HIVE) is a distributed computing environment used for healthcare-IT and biological research, including analysis of Next Generation Sequencing (NGS) data, preclinical, clinical and post market data, adverse events, metagenomic data, etc. Currently it is supported and continuously developed by US Food and Drug Administration (government domain), George Washington University (academic domain), and by DNA-HIVE, WHISE-Global and Embleema (commercial domain). HIVE currently operates fully functionally within the US FDA supporting wide variety (+60) of regulatory research and regulatory review projects as well as for supporting MDEpiNet medical device postmarket registries. Academic deployments of HIVE are used for research activities and publications in NGS analytics, cancer research, microbiome research and in educational programs for students at GWU. Commercial enterprises use HIVE for oncology, microbiology, vaccine manufacturing, gene editing, healthcare-IT, harmonization of real-world data, in preclinical research and clinical studies.
Infrastructure
HIVE is a massively parallel distributed computing environment where the distributed storage library and the distributed computational powerhouse are linked seamlessly. The system is both robust and flexible due to maintaining both storage and the metadata database on the same network. The distributed storage layer of software is the key component for file and archive management and is the backbone for the deposition pipeline. The data deposition back-end allows automatic uploads and downloads of external datasets into HIVE data repositories. The metadata database can be used to maintain specific information about extremely large files ingested into the system (big data) as well as metadata related to computations run on the system. This metadata then allows details of a computational pipeline to be brought up easily in the future in order to validate or replicate experiments. Since the metadata is associated with the computation, it stores the parameters of any computation in the system eliminating manual record keeping.
Differentiating HIVE from other object oriented databases is that HIVE implements a set of unified APIs to search, view, and manipulate data of all types. The system also facilitates a highly secure hierarchical access control and permission system, allowing determination of data access privileges in a finely granular manner without creating a multiplicity of rules in the security subsystem. The security model, designed for sensitive data, provides comprehensive control and auditing functionality in compliance with HIVE's designation as a FISMA Moderate system.
HIVE technological capabilities
- Data-retrieval: the HIVE is capable of retrieving data from a variety of sources such as local, cloud-based or network storage, sequencing instruments, and from http, ftp and sftp repositories. Additionally, HIVE implements the sophisticated handshake protocols with existing large scale data platforms such as NIH/NCBI to download large amounts of reference genomic or sequence read data on behalf of users in an easy and accurate manner.
- Data-warehousing: HIVE honeycomb data model was specifically created for adopting complex hierarchy of scientific datatypes, providing a platform for standardization and provenance of data within the framework of object-oriented data models. By using an integrated data-engine, honeycomb, HIVE contributes to the veracity of biomedical computations and helps ensure reproducibility, and harmonization of bio-computational processes.
- Security: HIVE-honeycomb employs a hierarchical security control system, allowing the determination of access privileges in an acutely granular manner without overwhelming the security subsystem with a multiplicity of rules. It provides on the fly encryption/decryption of PII and is compliant with the highest security protocols as requested for systems authorized to operate in regulatory FISMA moderate environments.

- Integration: HIVE provides unified Application Program Interface (API) to search, edit, view, secure, share and manipulate data and computations of all types. As an Integrator platform HIVE provides developers means to develop (C/C++, Python, Perl, JavaScript, R) and integrate existing almost any open source or commercial tools using generic adaptation framework to integrate command line tools. Additionally session controlled web-API provides means to drive HIVE to perform data quality control and complex computations on behalf of remote users. Currently there are tens of big data analytics tools in production HIVE and dozens more being developed; these include but are not limited to DNA-, RNA-, Transposon-, Chip-, Immune-sequencing), de novo assembly, population genomics metagenomic sequencing, differential profiling, statistical, classification and clusterization utilities to study bacteria, viruses, human germline and somatic profiles, quasispecies, infections, pathogens.
- Computations: Unlike many virtual computing environments, HIVE virtualizes services, not processes: it provides computations as a service by introducing agnostic abstraction layer between hardware, software and the computational tasks requested by users. The novel paradigm of relocating computations closer to the data, instead of moving data to computing cores has proven to be the key for optimal flow of tasks and data through network infrastructure.
- Visualization: HIVE provides number of scientific visualization components using technologies as HTML5, SVG, D3JS within its Data Driven Document context. The native data and metadata and computational results provided in JSON, CSV-based communication protocols, which are used to generate interactive, user driven, customizable tools allow bioinformaticians to manipulate terabytes of extra-large data using only an Internet browser.
HIVE open source
FDA launched HIVE Open Source as a platform to support end to end needs for NGS analytics. https://github.com/FDA/fda-hive
HIVE biocompute harmonization platform is at the core of High-throughput Sequencing Computational Standards for Regulatory Sciences (HTS-CSRS) project. Its mission is to provide the scientific community with a framework to harmonize biocomputing, promote interoperability, and verify bioinformatics protocols (https://hive.biochemistry.gwu.edu/htscsrs). For more information, see the project description on the FDA Extramural Research page (https://www.fda.gov/ScienceResearch/SpecialTopics/RegulatoryScience/ucm491893.htm
HIVE architecture
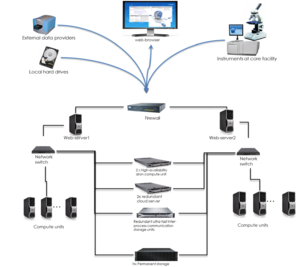
-
Hardware architecture: At the core of HIVE there exists a solid backbone hardware made of few redundant critical components and scalable compute and storage units. The diagram at the right demonstrates the connectivity and components assignations for such HIVE cluster. Core components providing the vital functions for HIVE cloud include
- web servers facing outside through the high-end secure firewall to support web-portal functionality;
- cloud servers are the core functional units orchestrating distributed storage and computations workflows through complex queuing and prioritization schemas;
- high availability drone hardware serves as a computational unit for scientific visualization and user interface support functionalities;
- ultra-fast inter-process communication storage units organize distributed computations data interchange staging arena.
- switches and firewall hardware organize the secure high performance network environment for HIVE cloud.
- permanent storage units each are designed to store hundreds of terabytes of NGS data and reference genomes as well as storage for computational results and personal user files.
Sub-clusters of scalable high performance high density compute cores are there to serve as a powerhouse for extra-large distributed parallelized computations of NGS algorithmics. System is extremely scalable and has deployment instances ranging from a single HIVE in a box appliance to massive enterprise level systems of thousands of compute units.
- Software architecture: HIVE software infrastructure consists of layers incrementally providing more functionality.

- The Kernel backbone layer provides integration with heterogeneous hardware and operating system platforms.
- HIVE cloud backbone supports distributed storage, security and computing environment.
- Science backbone represents set of low level scientific libraries to perform variety of scientific computations, mathematical apparatus for chemical, biological, statistical and other purely scientific concepts
- CGI and Java-script layers provide web-portal and web-application compatibility layers.
- Low level libraries provide Application Programming Interface (API) for developing tools and utilities.
- Integrated apps provide major NGS tool arsenal
- Web-apps and HIVE –portal provide web-portal functionality
Public Presentations
- Dr. Vahan Simonyan and Dr. Raja Mazumder presented at the NIH Frontiers in Data Science about HIVE acting as a bridge between research and regulatory analytics. Simonyan also presented on the topic at the 2014 Bio-IT World Expo.
- HIVE was additionally discussed in FedScoop.
- Inside the HIVE, the FDA's Multi-Omics Compute Architecture, BioIT World.
External links
- The public version of HIVE is at https://hive.biochemistry.gwu.edu/dna.cgi?cmd=about