
In bioinformatics, neighbor joining is a bottom-up (agglomerative) clustering method for the creation of phylogenetic trees, created by Naruya Saitou and Masatoshi Nei in 1987. Usually based on DNA or protein sequence data, the algorithm requires knowledge of the distance between each pair of taxa (e.g., species or sequences) to create the phylogenetic tree.
The algorithm

Neighbor joining takes a distance matrix, which specifies the distance between each pair of taxa, as input. The algorithm starts with a completely unresolved tree, whose topology corresponds to that of a star network, and iterates over the following steps, until the tree is completely resolved, and all branch lengths are known:
- Based on the current distance matrix, calculate a matrix (defined below).
- Find the pair of distinct taxa i and j (i.e. with ) for which is smallest. Make a new node that joins the taxa i and j, and connect the new node to the central node. For example, in part (B) of the figure at right, node u is created to join f and g.
- Calculate the distance from each of the taxa in the pair to this new node.
- Calculate the distance from each of the taxa outside of this pair to the new node.
- Start the algorithm again, replacing the pair of joined neighbors with the new node and using the distances calculated in the previous step.



The Q-matrix
Based on a distance matrix relating the taxa, calculate the x matrix as follows:

-
()

where is the distance between taxa and .



Distance from the pair members to the new node
For each of the taxa in the pair being joined, use the following formula to calculate the distance to the new node:
-
()
![\delta (f,u)={\frac {1}{2}}d(f,g)+{\frac {1}{2(n-2)}}\left[\sum _{{k=1}}^{n}d(f,k)-\sum _{{k=1}}^{n}d(g,k)\right]\quad](https://wikimedia.org/api/rest_v1/media/math/render/svg/fbb5a4b2a6fbec48a4bbc6d6fc1e351e5eb851e0)
and:

Taxa and are the paired taxa and is the newly created node. The branches joining and and and , and their lengths, and are part of the tree which is gradually being created; they neither affect nor are affected by later neighbor-joining steps.





Distance of the other taxa from the new node
For each taxon not considered in the previous step, we calculate the distance to the new node as follows:
-
()
![d(u,k)={\frac {1}{2}}[d(f,k)+d(g,k)-d(f,g)]](https://wikimedia.org/api/rest_v1/media/math/render/svg/29d8e77a0543fb3258d08396a6fb44d387a92ad8)
where is the new node, is the node which we want to calculate the distance to and and are the members of the pair just joined.

Complexity
Neighbor joining on a set of taxa requires iterations. At each step one has to build and search a matrix. Initially the matrix is size , then the next step it is , etc. Implementing this in a straightforward way leads to an algorithm with a time complexity of ; implementations exist which use heuristics to do much better than this on average.




Example
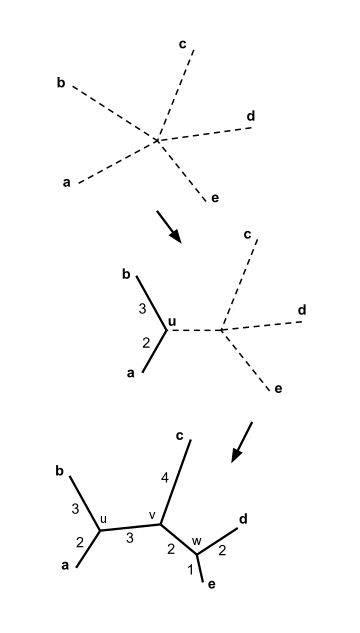
Let us assume that we have five taxa and the following distance matrix :


| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | 0 | 5 | 9 | 9 | 8 |
| b | 5 | 0 | 10 | 10 | 9 |
| c | 9 | 10 | 0 | 8 | 7 |
| d | 9 | 10 | 8 | 0 | 3 |
| e | 8 | 9 | 7 | 3 | 0 |
First step
First joining
We calculate the values by equation (1). For example:



We obtain the following values for the matrix (the diagonal elements of the matrix are not used and are omitted here):
| a | b | c | d | e | |
|---|---|---|---|---|---|
| a | −50 | −38 | −34 | −34 | |
| b | −50 | −38 | −34 | −34 | |
| c | −38 | −38 | −40 | −40 | |
| d | −34 | −34 | −40 | −48 | |
| e | −34 | −34 | −40 | −48 |
In the example above, . This is the smallest value of , so we join elements and .



First branch length estimation
Let denote the new node. By equation (2), above, the branches joining and to then have lengths:
![{\displaystyle \delta (a,u)={\frac {1}{2}}d(a,b)+{\frac {1}{2(5-2)}}\left[\sum _{k=1}^{5}d(a,k)-\sum _{k=1}^{5}d(b,k)\right]\quad ={\frac {5}{2}}+{\frac {31-34}{6}}=2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/37ab7ad46b3277cb0d8fa097d54007520aadb1df)

First distance matrix update
We then proceed to update the initial distance matrix into a new distance matrix (see below), reduced in size by one row and one column because of the joining of with into their neighbor . Using equation (3) above, we compute the distance from to each of the other nodes besides and . In this case, we obtain:

![{\displaystyle d(u,c)={\frac {1}{2}}[d(a,c)+d(b,c)-d(a,b)]={\frac {9+10-5}{2}}=7}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7f4eedbd420cf866e0aca938b6b92ac75e7a332d)
![{\displaystyle d(u,d)={\frac {1}{2}}[d(a,d)+d(b,d)-d(a,b)]={\frac {9+10-5}{2}}=7}](https://wikimedia.org/api/rest_v1/media/math/render/svg/4c547916160e8c48cdf86f8c07bf9dc4fb079aa1)
![{\displaystyle d(u,e)={\frac {1}{2}}[d(a,e)+d(b,e)-d(a,b)]={\frac {8+9-5}{2}}=6}](https://wikimedia.org/api/rest_v1/media/math/render/svg/498737ead33eb4e18634803a7c2a940091865cb1)
The resulting distance matrix is:
| u | c | d | e | |
|---|---|---|---|---|
| u | 0 | 7 | 7 | 6 |
| c | 7 | 0 | 8 | 7 |
| d | 7 | 8 | 0 | 3 |
| e | 6 | 7 | 3 | 0 |
Bold values in correspond to the newly calculated distances, whereas italicized values are not affected by the matrix update as they correspond to distances between elements not involved in the first joining of taxa.
Second step
Second joining
The corresponding matrix is:

| u | c | d | e | |
|---|---|---|---|---|
| u | −28 | −24 | −24 | |
| c | −28 | −24 | −24 | |
| d | −24 | −24 | −28 | |
| e | −24 | −24 | −28 |
We may choose either to join and , or to join and ; both pairs have the minimal value of , and either choice leads to the same result. For concreteness, let us join and and call the new node .





Second branch length estimation
The lengths of the branches joining and to can be calculated:
![{\displaystyle \delta (u,v)={\frac {1}{2}}d(u,c)+{\frac {1}{2(4-2)}}\left[\sum _{k=1}^{4}d(u,k)-\sum _{k=1}^{4}d(c,k)\right]\quad ={\frac {7}{2}}+{\frac {20-22}{4}}=3}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a469c064887abf42cd02ed9383f0fabff3d50379)

The joining of the elements and the branch length calculation help drawing the neighbor joining tree as shown in the figure.
Second distance matrix update
The updated distance matrix for the remaining 3 nodes, , , and , is now computed:

![{\displaystyle d(v,d)={\frac {1}{2}}[d(u,d)+d(c,d)-d(u,c)]={\frac {7+8-7}{2}}=4}](https://wikimedia.org/api/rest_v1/media/math/render/svg/9a149fca7dbf5339b8aaf177e55baf3ae19e3de6)
![{\displaystyle d(v,e)={\frac {1}{2}}[d(u,e)+d(c,e)-d(u,c)]={\frac {6+7-7}{2}}=3}](https://wikimedia.org/api/rest_v1/media/math/render/svg/75942d802678c69bac9b44e8b213994e490fe44c)
| v | d | e | |
|---|---|---|---|
| v | 0 | 4 | 3 |
| d | 4 | 0 | 3 |
| e | 3 | 3 | 0 |
Final step
The tree topology is fully resolved at this point. However, for clarity, we can calculate the matrix. For example:


| v | d | e | |
|---|---|---|---|
| v | −10 | −10 | |
| d | −10 | −10 | |
| e | −10 | −10 |
For concreteness, let us join and and call the last node . The lengths of the three remaining branches can be calculated:

![{\displaystyle \delta (v,w)={\frac {1}{2}}d(v,d)+{\frac {1}{2(3-2)}}\left[\sum _{k=1}^{3}d(v,k)-\sum _{k=1}^{3}d(d,k)\right]\quad ={\frac {4}{2}}+{\frac {7-7}{2}}=2}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7ef24fb03c3726d7607adbd331c3301b26e40551)


The neighbor joining tree is now complete, as shown in the figure.
Conclusion: additive distances
This example represents an idealized case: note that if we move from any taxon to any other along the branches of the tree, and sum the lengths of the branches traversed, the result is equal to the distance between those taxa in the input distance matrix. For example, going from to we have . A distance matrix whose distances agree in this way with some tree is said to be 'additive', a property which is rare in practice. Nonetheless it is important to note that, given an additive distance matrix as input, neighbor joining is guaranteed to find the tree whose distances between taxa agree with it.

Neighbor joining as minimum evolution
Neighbor joining may be viewed as a greedy heuristic for the Balanced Minimum Evolution (BME) criterion. For each topology, BME defines the tree length (sum of branch lengths) to be a particular weighted sum of the distances in the distance matrix, with the weights depending on the topology. The BME optimal topology is the one which minimizes this tree length. Neighbor joining at each step greedily joins that pair of taxa which will give the greatest decrease in the estimated tree length. This procedure does not guarantee to find the optimum for the BME criterion, although it often does and is usually quite close.
Advantages and disadvantages
The main virtue of NJ is that it is fast as compared to least squares, maximum parsimony and maximum likelihood methods. This makes it practical for analyzing large data sets (hundreds or thousands of taxa) and for bootstrapping, for which purposes other means of analysis (e.g. maximum parsimony, maximum likelihood) may be computationally prohibitive.
Neighbor joining has the property that if the input distance matrix is correct, then the output tree will be correct. Furthermore, the correctness of the output tree topology is guaranteed as long as the distance matrix is 'nearly additive', specifically if each entry in the distance matrix differs from the true distance by less than half of the shortest branch length in the tree. In practice the distance matrix rarely satisfies this condition, but neighbor joining often constructs the correct tree topology anyway. The correctness of neighbor joining for nearly additive distance matrices implies that it is statistically consistent under many models of evolution; given data of sufficient length, neighbor joining will reconstruct the true tree with high probability. Compared with UPGMA and WPGMA, neighbor joining has the advantage that it does not assume all lineages evolve at the same rate (molecular clock hypothesis).
Nevertheless, neighbor joining has been largely superseded by phylogenetic methods that do not rely on distance measures and offer superior accuracy under most conditions. Neighbor joining has the undesirable feature that it often assigns negative lengths to some of the branches.
Implementations and variants
There are many programs available implementing neighbor joining. RapidNJ and NINJA are fast implementations with typical run times proportional to approximately the square of the number of taxa. BIONJ and Weighbor are variants of neighbor joining which improve on its accuracy by making use of the fact that the shorter distances in the distance matrix are generally better known than the longer distances. FastME is an implementation of the closely related balanced minimum evolution method.
See also
Other sources
- Studier JA, Keppler KJ (1988). "A note on the Neighbor-Joining algorithm of Saitou and Nei". Mol Biol Evol. 5 (6): 729–731. doi:10.1093/oxfordjournals.molbev.a040527. PMID 3221794.
- Martin Simonsen; Thomas Mailund; Christian N. S. Pedersen (2008). Rapid Neighbour Joining. Proceedings of WABI. Lecture Notes in Computer Science. Vol. 5251. pp. 113–122. CiteSeerX 10.1.1.218.2078. doi:10.1007/978-3-540-87361-7_10. ISBN 978-3-540-87360-0.
External links
- The Neighbor-Joining Method — a tutorial
| Relevant fields | ||
|---|---|---|
| Basic concepts | ||
| Inference methods | ||
| Current topics | ||
| Group traits | ||
| Group types | ||
| Nomenclature | ||