

Protein biosynthesis (or protein synthesis) is a core biological process, occurring inside cells, balancing the loss of cellular proteins (via degradation or export) through the production of new proteins. Proteins perform a number of critical functions as enzymes, structural proteins or hormones. Protein synthesis is a very similar process for both prokaryotes and eukaryotes but there are some distinct differences.
Protein synthesis can be divided broadly into two phases - transcription and translation. During transcription, a section of DNA encoding a protein, known as a gene, is converted into a template molecule called messenger RNA (mRNA). This conversion is carried out by enzymes, known as RNA polymerases, in the nucleus of the cell. In eukaryotes, this mRNA is initially produced in a premature form (pre-mRNA) which undergoes post-transcriptional modifications to produce mature mRNA. The mature mRNA is exported from the cell nucleus via nuclear pores to the cytoplasm of the cell for translation to occur. During translation, the mRNA is read by ribosomes which use the nucleotide sequence of the mRNA to determine the sequence of amino acids. The ribosomes catalyze the formation of covalent peptide bonds between the encoded amino acids to form a polypeptide chain.
Following translation the polypeptide chain must fold to form a functional protein; for example, to function as an enzyme the polypeptide chain must fold correctly to produce a functional active site. To adopt a functional three-dimensional (3D) shape, the polypeptide chain must first form a series of smaller underlying structures called secondary structures. The polypeptide chain in these secondary structures then folds to produce the overall 3D tertiary structure. Once correctly folded, the protein can undergo further maturation through different post-translational modifications. Post-translational modifications can alter the protein's ability to function, where it is located within the cell (e.g. cytoplasm or nucleus) and the protein's ability to interact with other proteins.
Protein biosynthesis has a key role in disease as changes and errors in this process, through underlying DNA mutations or protein misfolding, are often the underlying causes of a disease. DNA mutations change the subsequent mRNA sequence, which then alters the mRNA encoded amino acid sequence. Mutations can cause the polypeptide chain to be shorter by generating a stop sequence which causes early termination of translation. Alternatively, a mutation in the mRNA sequence changes the specific amino acid encoded at that position in the polypeptide chain. This amino acid change can impact the protein's ability to function or to fold correctly. Misfolded proteins are often implicated in disease as improperly folded proteins have a tendency to stick together to form dense protein clumps. These clumps are linked to a range of diseases, often neurological, including Alzheimer's disease and Parkinson's disease.
Transcription
Transcription occurs in the nucleus using DNA as a template to produce mRNA. In eukaryotes, this mRNA molecule is known as pre-mRNA as it undergoes post-transcriptional modifications in the nucleus to produce a mature mRNA molecule. However, in prokaryotes post-transcriptional modifications are not required so the mature mRNA molecule is immediately produced by transcription.


Initially, an enzyme known as a helicase acts on the molecule of DNA. DNA has an antiparallel, double helix structure composed of two, complementary polynucleotide strands, held together by hydrogen bonds between the base pairs. The helicase disrupts the hydrogen bonds causing a region of DNA - corresponding to a gene - to unwind, separating the two DNA strands and exposing a series of bases. Despite DNA being a double stranded molecule, only one of the strands acts as a template for pre-mRNA synthesis - this strand is known as the template strand. The other DNA strand (which is complementary to the template strand) is known as the coding strand.
Both DNA and RNA have intrinsic directionality, meaning there are two distinct ends of the molecule. This property of directionality is due to the asymmetrical underlying nucleotide subunits, with a phosphate group on one side of the pentose sugar and a base on the other. The five carbons in the pentose sugar are numbered from 1' (where ' means prime) to 5'. Therefore, the phosphodiester bonds connecting the nucleotides are formed by joining the hydroxyl group on the 3' carbon of one nucleotide to the phosphate group on the 5' carbon of another nucleotide. Hence, the coding strand of DNA runs in a 5' to 3' direction and the complementary, template DNA strand runs in the opposite direction from 3' to 5'.
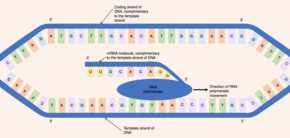
The enzyme RNA polymerase binds to the exposed template strand and reads from the gene in the 3' to 5' direction. Simultaneously, the RNA polymerase synthesizes a single strand of pre-mRNA in the 5'-to-3' direction by catalysing the formation of phosphodiester bonds between activated nucleotides (free in the nucleus) that are capable of complementary base pairing with the template strand. Behind the moving RNA polymerase the two strands of DNA rejoin, so only 12 base pairs of DNA are exposed at one time. RNA polymerase builds the pre-mRNA molecule at a rate of 20 nucleotides per second enabling the production of thousands of pre-mRNA molecules from the same gene in an hour. Despite the fast rate of synthesis, the RNA polymerase enzyme contains its own proofreading mechanism. The proofreading mechanisms allows the RNA polymerase to remove incorrect nucleotides (which are not complementary to the template strand of DNA) from the growing pre-mRNA molecule through an excision reaction. When RNA polymerases reaches a specific DNA sequence which terminates transcription, RNA polymerase detaches and pre-mRNA synthesis is complete.
The pre-mRNA molecule synthesized is complementary to the template DNA strand and shares the same nucleotide sequence as the coding DNA strand. However, there is one crucial difference in the nucleotide composition of DNA and mRNA molecules. DNA is composed of the bases - guanine, cytosine, adenine and thymine (G, C, A and T) - RNA is also composed of four bases - guanine, cytosine, adenine and uracil. In RNA molecules, the DNA base thymine is replaced by uracil which is able to base pair with adenine. Therefore, in the pre-mRNA molecule, all complementary bases which would be thymine in the coding DNA strand are replaced by uracil.
Post-transcriptional modifications

Once transcription is complete, the pre-mRNA molecule undergoes post-transcriptional modifications to produce a mature mRNA molecule.
There are 3 key steps within post-transcriptional modifications:
- Addition of a 5' cap to the 5' end of the pre-mRNA molecule
- Addition of a 3' poly(A) tail is added to the 3' end pre-mRNA molecule
- Removal of introns via RNA splicing
The 5' cap is added to the 5' end of the pre-mRNA molecule and is composed of a guanine nucleotide modified through methylation. The purpose of the 5' cap is to prevent break down of mature mRNA molecules before translation, the cap also aids binding of the ribosome to the mRNA to start translation and enables mRNA to be differentiated from other RNAs in the cell. In contrast, the 3' Poly(A) tail is added to the 3' end of the mRNA molecule and is composed of 100-200 adenine bases. These distinct mRNA modifications enable the cell to detect that the full mRNA message is intact if both the 5' cap and 3' tail are present.
This modified pre-mRNA molecule then undergoes the process of RNA splicing. Genes are composed of a series of introns and exons, introns are nucleotide sequences which do not encode a protein while, exons are nucleotide sequences that directly encode a protein. Introns and exons are present in both the underlying DNA sequence and the pre-mRNA molecule, therefore, to produce a mature mRNA molecule encoding a protein, splicing must occur. During splicing, the intervening introns are removed from the pre-mRNA molecule by a multi-protein complex known as a spliceosome (composed of over 150 proteins and RNA). This mature mRNA molecule is then exported into the cytoplasm through nuclear pores in the envelope of the nucleus.
Translation

During translation, ribosomes synthesize polypeptide chains from mRNA template molecules. In eukaryotes, translation occurs in the cytoplasm of the cell, where the ribosomes are located either free floating or attached to the endoplasmic reticulum. In prokaryotes, which lack a nucleus, the processes of both transcription and translation occur in the cytoplasm.
Ribosomes are complex molecular machines, made of a mixture of protein and ribosomal RNA, arranged into two subunits (a large and a small subunit), which surround the mRNA molecule. The ribosome reads the mRNA molecule in a 5'-3' direction and uses it as a template to determine the order of amino acids in the polypeptide chain. To translate the mRNA molecule, the ribosome uses small molecules, known as transfer RNAs (tRNA), to deliver the correct amino acids to the ribosome. Each tRNA is composed of 70-80 nucleotides and adopts a characteristic cloverleaf structure due to the formation of hydrogen bonds between the nucleotides within the molecule. There are around 60 different types of tRNAs, each tRNA binds to a specific sequence of three nucleotides (known as a codon) within the mRNA molecule and delivers a specific amino acid.
The ribosome initially attaches to the mRNA at the start codon (AUG) and begins to translate the molecule. The mRNA nucleotide sequence is read in triplets - three adjacent nucleotides in the mRNA molecule correspond to a single codon. Each tRNA has an exposed sequence of three nucleotides, known as the anticodon, which are complementary in sequence to a specific codon that may be present in mRNA. For example, the first codon encountered is the start codon composed of the nucleotides AUG. The correct tRNA with the anticodon (complementary 3 nucleotide sequence UAC) binds to the mRNA using the ribosome. This tRNA delivers the correct amino acid corresponding to the mRNA codon, in the case of the start codon, this is the amino acid methionine. The next codon (adjacent to the start codon) is then bound by the correct tRNA with complementary anticodon, delivering the next amino acid to ribosome. The ribosome then uses its peptidyl transferase enzymatic activity to catalyze the formation of the covalent peptide bond between the two adjacent amino acids.
The ribosome then moves along the mRNA molecule to the third codon. The ribosome then releases the first tRNA molecule, as only two tRNA molecules can be brought together by a single ribosome at one time. The next complementary tRNA with the correct anticodon complementary to the third codon is selected, delivering the next amino acid to the ribosome which is covalently joined to the growing polypeptide chain. This process continues with the ribosome moving along the mRNA molecule adding up to 15 amino acids per second to the polypeptide chain. Behind the first ribosome, up to 50 additional ribosomes can bind to the mRNA molecule forming a polysome, this enables simultaneous synthesis of multiple identical polypeptide chains. Termination of the growing polypeptide chain occurs when the ribosome encounters a stop codon (UAA, UAG, or UGA) in the mRNA molecule. When this occurs, no tRNA can recognise it and a release factor induces the release of the complete polypeptide chain from the ribosome. Dr. Har Gobind Khorana, a scientist originating from India, decoded the RNA sequences for about 20 amino acids. He was awarded the Nobel prize in 1968, along with two other scientists, for his work.
Protein folding
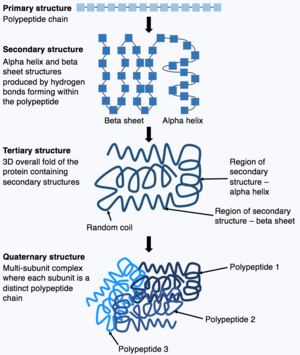
Once synthesis of the polypeptide chain is complete, the polypeptide chain folds to adopt a specific structure which enables the protein to carry out its functions. The basic form of protein structure is known as the primary structure, which is simply the polypeptide chain i.e. a sequence of covalently bonded amino acids. The primary structure of a protein is encoded by a gene. Therefore, any changes to the sequence of the gene can alter the primary structure of the protein and all subsequent levels of protein structure, ultimately changing the overall structure and function.
The primary structure of a protein (the polypeptide chain) can then fold or coil to form the secondary structure of the protein. The most common types of secondary structure are known as an alpha helix or beta sheet, these are small structures produced by hydrogen bonds forming within the polypeptide chain. This secondary structure then folds to produce the tertiary structure of the protein. The tertiary structure is the proteins overall 3D structure which is made of different secondary structures folding together. In the tertiary structure, key protein features e.g. the active site, are folded and formed enabling the protein to function. Finally, some proteins may adopt a complex quaternary structure. Most proteins are made of a single polypeptide chain, however, some proteins are composed of multiple polypeptide chains (known as subunits) which fold and interact to form the quaternary structure. Hence, the overall protein is a multi-subunit complex composed of multiple folded, polypeptide chain subunits e.g. haemoglobin.
Post-translation events
There are events that follow protein biosynthesis such as proteolysis and protein-folding. Proteolysis refers to the cleavage of proteins by proteases and the breakdown of proteins into amino acids by the action of enzymes.
Post-translational modifications
When protein folding into the mature, functional 3D state is complete, it is not necessarily the end of the protein maturation pathway. A folded protein can still undergo further processing through post-translational modifications. There are over 200 known types of post-translational modification, these modifications can alter protein activity, the ability of the protein to interact with other proteins and where the protein is found within the cell e.g. in the cell nucleus or cytoplasm. Through post-translational modifications, the diversity of proteins encoded by the genome is expanded by 2 to 3 orders of magnitude.
There are four key classes of post-translational modification:
- Cleavage
- Addition of chemical groups
- Addition of complex molecules
- Formation of intramolecular bonds
Cleavage
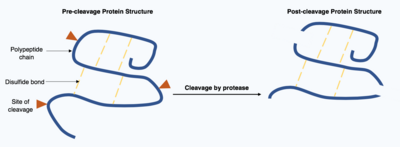
Cleavage of proteins is an irreversible post-translational modification carried out by enzymes known as proteases. These proteases are often highly specific and cause hydrolysis of a limited number of peptide bonds within the target protein. The resulting shortened protein has an altered polypeptide chain with different amino acids at the start and end of the chain. This post-translational modification often alters the proteins function, the protein can be inactivated or activated by the cleavage and can display new biological activities.
Addition of chemical groups

Following translation, small chemical groups can be added onto amino acids within the mature protein structure. Examples of processes which add chemical groups to the target protein include methylation, acetylation and phosphorylation.
Methylation is the reversible addition of a methyl group onto an amino acid catalyzed by methyltransferase enzymes. Methylation occurs on at least 9 of the 20 common amino acids, however, it mainly occurs on the amino acids lysine and arginine. One example of a protein which is commonly methylated is a histone. Histones are proteins found in the nucleus of the cell. DNA is tightly wrapped round histones and held in place by other proteins and interactions between negative charges in the DNA and positive charges on the histone. A highly specific pattern of amino acid methylation on the histone proteins is used to determine which regions of DNA are tightly wound and unable to be transcribed and which regions are loosely wound and able to be transcribed.
Histone-based regulation of DNA transcription is also modified by acetylation. Acetylation is the reversible covalent addition of an acetyl group onto a lysine amino acid by the enzyme acetyltransferase. The acetyl group is removed from a donor molecule known as acetyl coenzyme A and transferred onto the target protein.Histones undergo acetylation on their lysine residues by enzymes known as histone acetyltransferase. The effect of acetylation is to weaken the charge interactions between the histone and DNA, thereby making more genes in the DNA accessible for transcription.
The final, prevalent post-translational chemical group modification is phosphorylation. Phosphorylation is the reversible, covalent addition of a phosphate group to specific amino acids (serine, threonine and tyrosine) within the protein. The phosphate group is removed from the donor molecule ATP by a protein kinase and transferred onto the hydroxyl group of the target amino acid, this produces adenosine diphosphate as a biproduct. This process can be reversed and the phosphate group removed by the enzyme protein phosphatase. Phosphorylation can create a binding site on the phosphorylated protein which enables it to interact with other proteins and generate large, multi-protein complexes. Alternatively, phosphorylation can change the level of protein activity by altering the ability of the protein to bind its substrate.
Addition of complex molecules
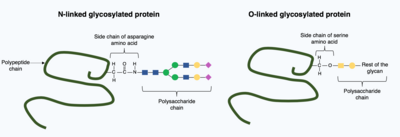
Post-translational modifications can incorporate more complex, large molecules into the folded protein structure. One common example of this is glycosylation, the addition of a polysaccharide molecule, which is widely considered to be most common post-translational modification.
In glycosylation, a polysaccharide molecule (known as a glycan) is covalently added to the target protein by glycosyltransferases enzymes and modified by glycosidases in the endoplasmic reticulum and Golgi apparatus. Glycosylation can have a critical role in determining the final, folded 3D structure of the target protein. In some cases glycosylation is necessary for correct folding. N-linked glycosylation promotes protein folding by increasing solubility and mediates the protein binding to protein chaperones. Chaperones are proteins responsible for folding and maintaining the structure of other proteins.
There are broadly two types of glycosylation, N-linked glycosylation and O-linked glycosylation. N-linked glycosylation starts in the endoplasmic reticulum with the addition of a precursor glycan. The precursor glycan is modified in the Golgi apparatus to produce complex glycan bound covalently to the nitrogen in an asparagine amino acid. In contrast, O-linked glycosylation is the sequential covalent addition of individual sugars onto the oxygen in the amino acids serine and threonine within the mature protein structure.
Formation of covalent bonds
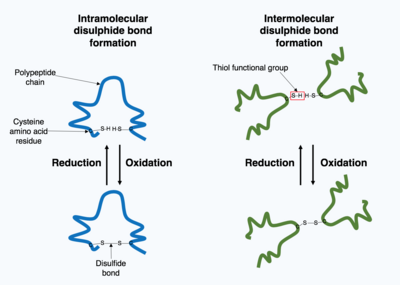
Many proteins produced within the cell are secreted outside the cell to function as extracellular proteins. Extracellular proteins are exposed to a wide variety of conditions. To stabilize the 3D protein structure, covalent bonds are formed either within the protein or between the different polypeptide chains in the quaternary structure. The most prevalent type is a disulfide bond (also known as a disulfide bridge). A disulfide bond is formed between two cysteine amino acids using their side chain chemical groups containing a Sulphur atom, these chemical groups are known as thiol functional groups. Disulfide bonds act to stabilize the pre-existing structure of the protein. Disulfide bonds are formed in an oxidation reaction between two thiol groups and therefore, need an oxidizing environment to react. As a result, disulfide bonds are typically formed in the oxidizing environment of the endoplasmic reticulum catalyzed by enzymes called protein disulfide isomerases. Disulfide bonds are rarely formed in the cytoplasm as it is a reducing environment.
Role of protein synthesis in disease
Many diseases are caused by mutations in genes, due to the direct connection between the DNA nucleotide sequence and the amino acid sequence of the encoded protein. Changes to the primary structure of the protein can result in the protein mis-folding or malfunctioning. Mutations within a single gene have been identified as a cause of multiple diseases, including sickle cell disease, known as single gene disorders.
Sickle cell disease

Sickle cell disease is a group of diseases caused by a mutation in a subunit of hemoglobin, a protein found in red blood cells responsible for transporting oxygen. The most dangerous of the sickle cell diseases is known as sickle cell anemia. Sickle cell anemia is the most common homozygous recessive single gene disorder, meaning the affected individual must carry a mutation in both copies of the affected gene (one inherited from each parent) to experience the disease. Hemoglobin has a complex quaternary structure and is composed of four polypeptide subunits - two A subunits and two B subunits. Patients with sickle cell anemia have a missense or substitution mutation in the gene encoding the hemoglobin B subunit polypeptide chain. A missense mutation means the nucleotide mutation alters the overall codon triplet such that a different amino acid is paired with the new codon. In the case of sickle cell anemia, the most common missense mutation is a single nucleotide mutation from thymine to adenine in the hemoglobin B subunit gene. This changes codon 6 from encoding the amino acid glutamic acid to encoding valine.
This change in the primary structure of the hemoglobin B subunit polypeptide chain alters the functionality of the hemoglobin multi-subunit complex in low oxygen conditions. When red blood cells unload oxygen into the tissues of the body, the mutated haemoglobin protein starts to stick together to form a semi-solid structure within the red blood cell. This distorts the shape of the red blood cell, resulting in the characteristic "sickle" shape, and reduces cell flexibility. This rigid, distorted red blood cell can accumulate in blood vessels creating a blockage. The blockage prevents blood flow to tissues and can lead to tissue death which causes great pain to the individual.
Cancer
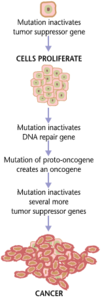
Cancers form as a result of gene mutations as well as improper protein translation. In addition to cancer cells proliferating abnormally, they suppress the expression of anti-apoptotic or pro-apoptotic genes or proteins. Most cancer cells see a mutation in the signaling protein Ras, which functions as an on/off signal transductor in cells. In cancer cells, the RAS protein becomes persistently active, thus promoting the proliferation of the cell due to the absence of any regulation. Additionally, most cancer cells carry two mutant copies of the regulator gene p53, which acts as a gatekeeper for damaged genes and initiates apoptosis in malignant cells. In its absence, the cell cannot initiate apoptosis or signal for other cells to destroy it.
As the tumor cells proliferate, they either remain confined to one area and are called benign, or become malignant cells that migrate to other areas of the body. Oftentimes, these malignant cells secrete proteases that break apart the extracellular matrix of tissues. This then allows the cancer to enter its terminal stage called Metastasis, in which the cells enter the bloodstream or the lymphatic system to travel to a new part of the body.
See also
- Central dogma of molecular biology
- Gene expression
- Genetic code
- Post-translational modification
- Protein folding
External links
- A more advanced video detailing the different types of post-translational modifications and their chemical structures
- A useful video visualising the process of converting DNA to protein via transcription and translation
- Video visualising the process of protein folding from the non-functional primary structure to a mature, folded 3D protein structure with reference to the role of mutations and protein mis-folding in disease